CoP Pipeline

We propose Composition-of-Principles (CoP), an innovative agentic red-teaming framework for large language models that orchestrates multiple human-provided jailbreak principles to effectively bypass safety guardrails. Our approach operates through a transparent, modular architecture that automatically discovers and combines jailbreak strategies tailored to specific harmful queries, significantly improving attack efficiency and effectiveness across diverse target models. The framework utilizes three core components: a Red-Teaming Agent that transforms harmful queries into sophisticated jailbreak prompts by combining multiple principles (such as Expand, Generate, and Phrase Insertion); a Target LLM that receives these prompts; and a Judge LLM that evaluates both jailbreak success and semantic similarity to ensure relevance. CoP incorporates an initial seed prompt generation phase to overcome direct refusal issues, followed by iterative refinement that systematically improves jailbreak effectiveness based on evaluation feedback. This methodology demonstrates unprecedented performance, achieving up to 22 times higher attack success rates against strongly aligned models like Claude-3.5 Sonnet while requiring up to 17.2 times fewer queries compared to existing approaches. Importantly, CoP maintains complete transparency by explicitly showing which principle combinations are most effective for different models, facilitating better defense mechanisms. Our comprehensive experiments reveal that expansion-based strategies consistently outperform other approaches across both open-source and commercial models, with CoP even successfully jailbreaking safety-enhanced models specifically designed to resist such attacks. This framework's extensibility allows easy incorporation of new principles without retraining, making it an invaluable tool for AI safety research and the development of more robust defensive measures against evolving jailbreak techniques.
CoP Performance
CoP Achieves State-of-the-Art Attack Performance
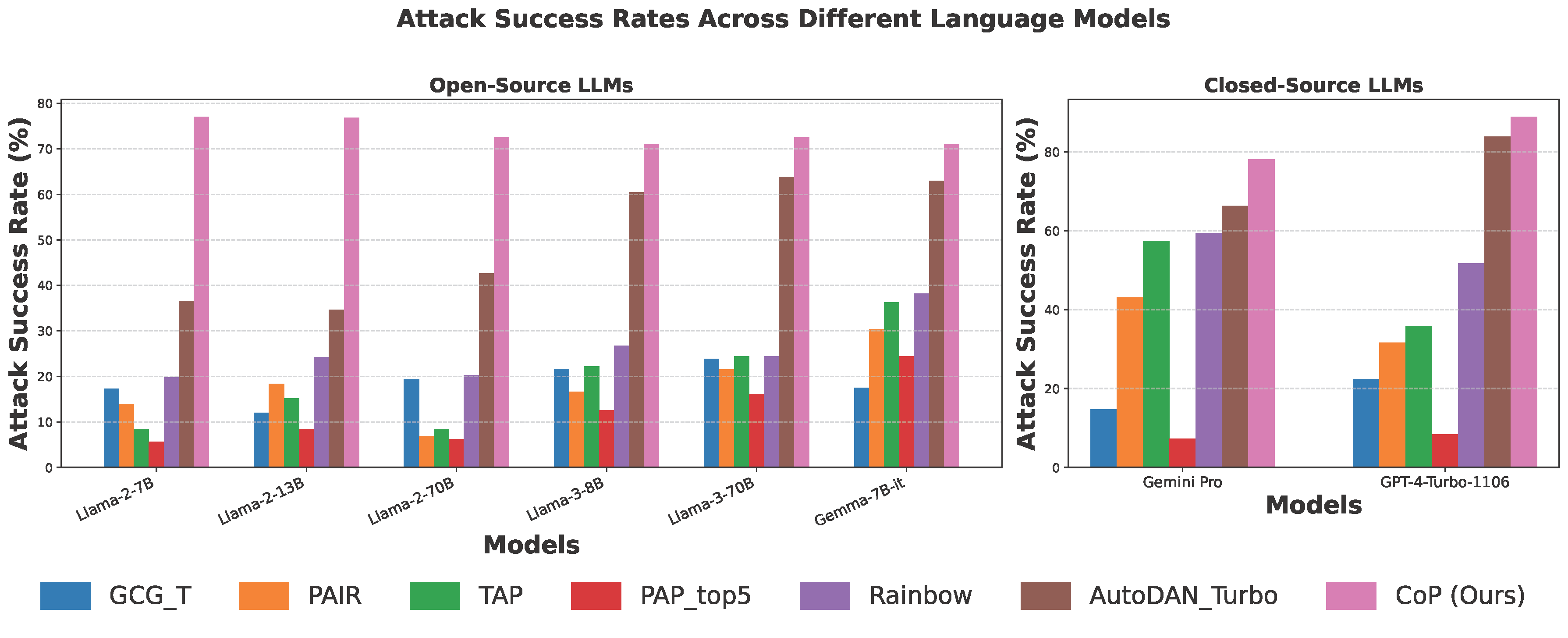
The CoP method demonstrates superior effectiveness in jailbreaking language models across various architectures and sizes (71-77% success rate) on Harmbench dataset, outperforming baseline methods by 2.0-13.8× and maintaining a 1.1-2.2× advantage over the strongest competitor. It successfully bypasses safety measures in models previously resistant to attacks, suggesting CoP exploits a universal vulnerability in LLM safety mechanisms. When tested on commercial models, CoP achieved even higher success rates (88.75% on GPT-4-Turbo and 78% on Gemini Pro 1.5), representing 1.0-10.6× improvements over existing baselines and revealing previously hidden weaknesses in highly aligned proprietary systems.
CoP Effectively Bypasses Safty-Enhanced LLM
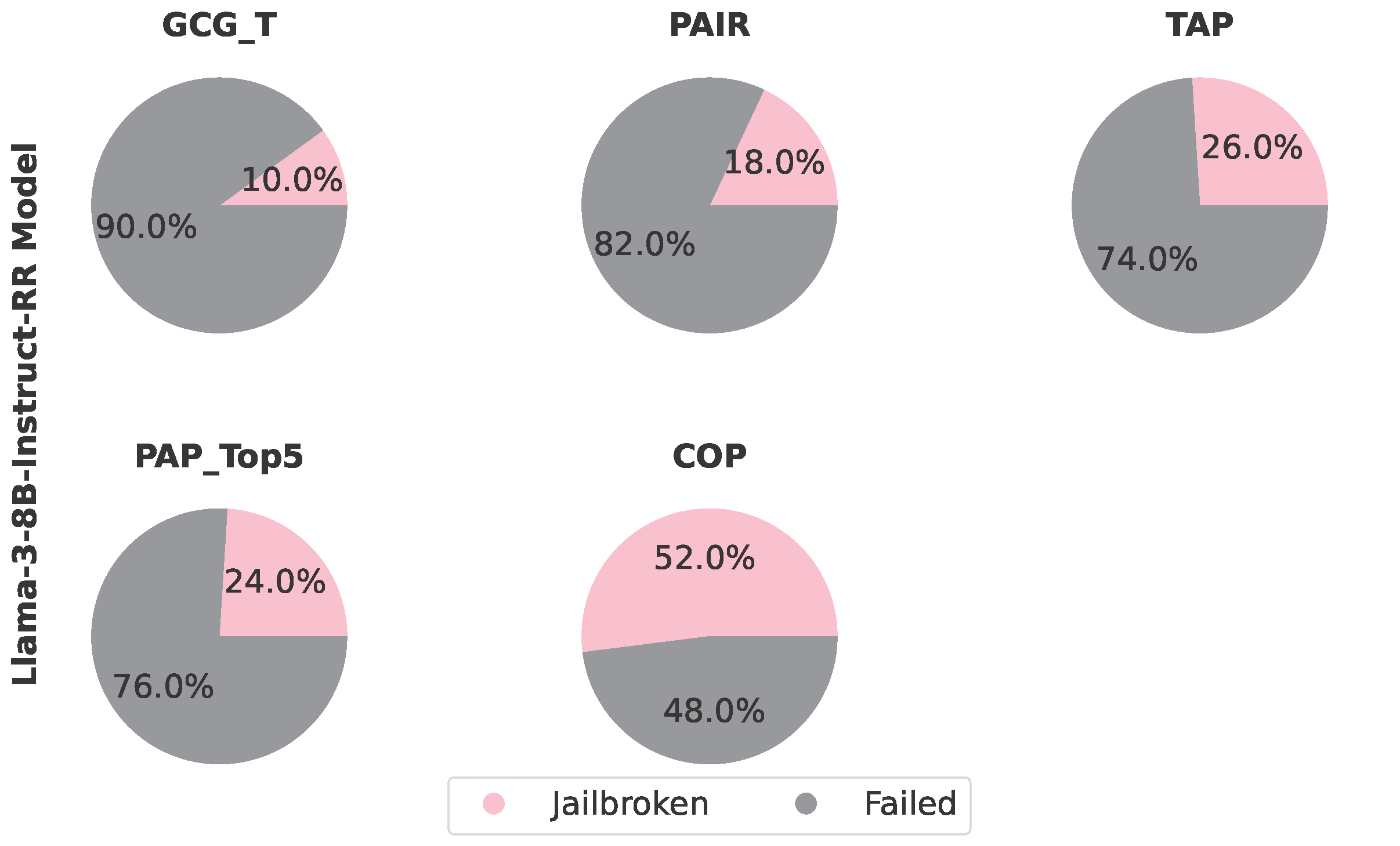
CoP was tested against Llama-3-8B-Instruct-RR, a safety-enhanced model using Representation Rerouting to interrupt harmful content generation. In experiments with 50 Harmbench queries, CoP achieved a 52% attack success rate, significantly outperforming all baselines: 2.0× better than TAP (26%), 2.2× better than PAP-top5 (24%), 2.9× better than PAIR (18%), and 5.2× better than GCG-T (10%). Despite Llama-3-8B-Instruct-RR's circuit-breaker* modifications designed to redirect harmful internal representations, CoP successfully bypassed these guardrails through structured sequences of pretenses. This reveals that even models with explicit representation-level safety controls remain vulnerable to advanced attack strategies, highlighting persistent challenges in developing robustly aligned LLMs and demonstrating CoP's exceptional red-teaming capabilities.
*Improving Alignment and Robustness with Circuit Breakers
CoP Significantly Reduces Query Overhead

CoP demonstrates superior query efficiency compared to leading baselines (PAIR, TAP, and AutoDAN-Turbo) in jailbreaking attempts. With a 20-iteration maximum, CoP consistently outperforms all competitors across tested models. For Gemini, CoP requires only 1.357 queries on average compared to PAIR (6.5 queries), TAP (12.79 queries), and AutoDAN-Turbo (2.76 queries). When attacking GPT-4, CoP needs just 1.512 queries versus PAIR's 12.11, TAP's 26.08, and AutoDAN-Turbo's 5.63. Notably, the analysis only counts queries for successful jailbreaks; including failed attempts would further increase query counts for all baselines.
Commonly Used Strategies in Successful Jailbreaks

Analyzing 150 random Harmbench queries across multiple LLMs (Llama-2-7B/13B-Chat, Llama-3-8B-Instruct, Gemma-7B-it, GPT-4-1106-Preview, and Gemini Pro 1.5), we identified which CoP strategies were most effective for successful jailbreaking. Expansion-based strategies clearly dominate successful jailbreak attempts. The standalone "expand" principle was most frequent (12%), demonstrating how additional contextual information effectively dilutes harmful intent. "Expand + phrase insertion" followed at 9.8%, showing how expanded content creates opportunities to embed trigger phrases within seemingly benign text, reducing detectability. Multi-layered approaches like "generate ⊕ expand ⊕ rephrase" (5.7%) were also effective, creating new content while adding contextual complexity and restructuring linguistic patterns. This expansion-focused methodology consistently outperformed reductive approaches, with "shorten" completely absent among effective techniques. This suggests safety alignment mechanisms are more vulnerable to content dilution than content condensation.